
Vultr Docs
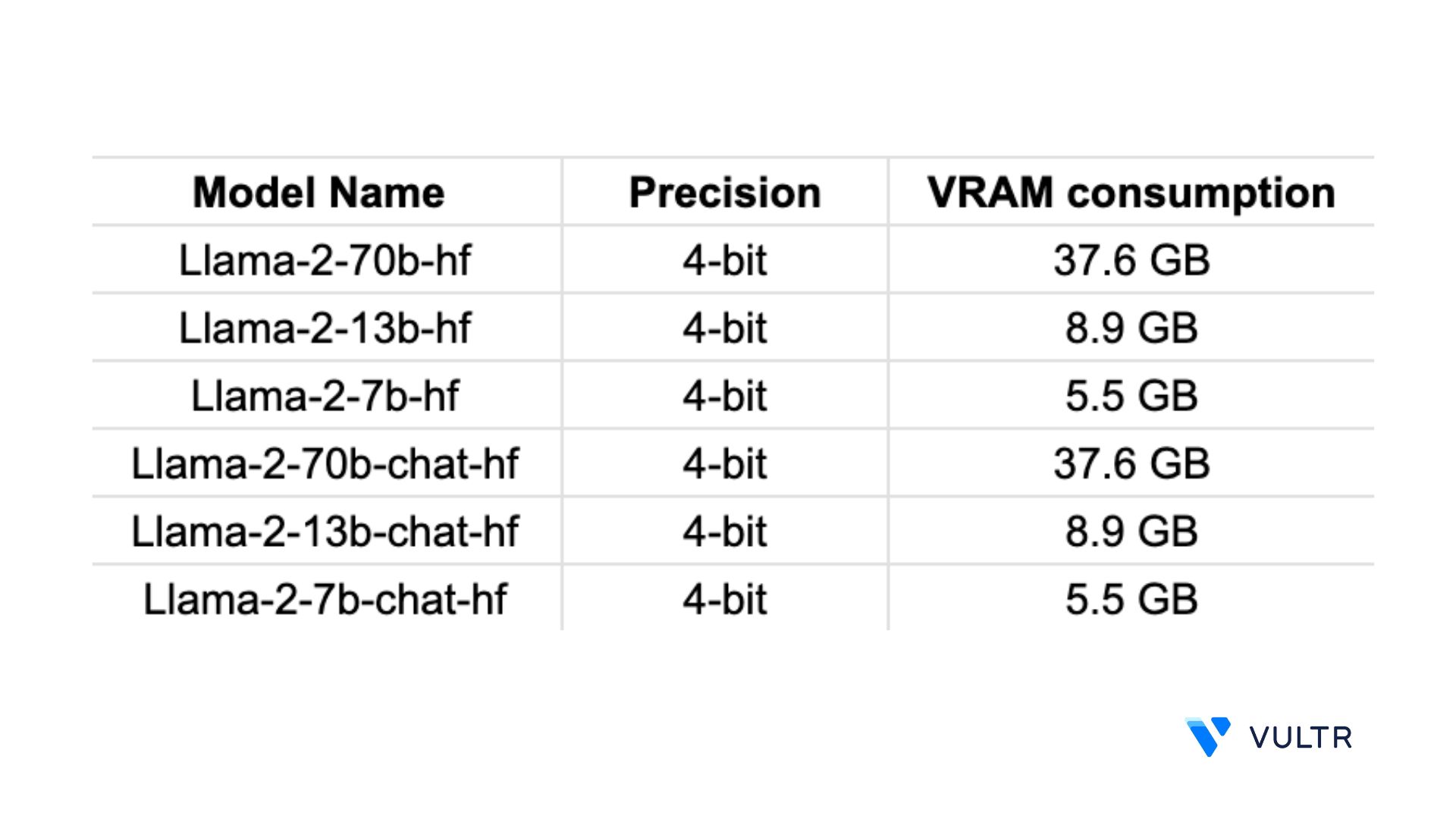
Llama2 7B-Chat on RTX 2070S with bitsandbytes FP4 Ryzen 5 3600 32GB RAM. . This repo contains GPTQ model files for Metas Llama 2 13B. Consider the requirements for this project We will be using the meta-llamaLlama-2-7b-hf which. Variations Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned. Below is a table outlining the GPU VRAM requirements for the models all models are in bfloat16 mode with a single. LlaMa 2 is a large language AI model capable of generating text and code in response..
Medium balanced quality - prefer using Q4_K_M. Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion. You can choose any version you prefer but for this guide we will be downloading the llama-2-7b. . Examples on this page use the llama-2-7b-chatQ5_K_Mgguf model 467 GB but try different models to identify one. NF4 is a static method used by QLoRA to load a model in 4-bit precision to perform fine-tuning. . WasmEdge now supports running llama2 series of models in Rust We will use this example project to..
. Small very high quality loss - prefer using Q3_K_M. Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion. On a newer computer 13B quantised to INT8 httpshuggingfacecoTheBlokeLlama-2. Still wondering how to run chat mode session then saving the conversation Will check this page again later. How are you Run in interactive mode Main -m modelsllama-2-13b-chatggmlv3q4_0bin --color -. Download 3B ggml model here llama-213b-chatggmlv3q4_0bin Download takes a while due to the size..
Small very high quality loss - prefer using Q3_K_M. This repo contains GGUF format model files for Metas Llama 2 7B. . WEB Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7. . WEB Llama 2 is released by Meta Platforms Inc This model is trained on 2 trillion tokens and by. WEB Coupled with the release of Llama models and parameter-efficient techniques to fine-tune them LoRA. WEB Run the Python script You should now have the model downloaded to a..

Easy With Ai




Komentar